Getting progress out of a Redis SCAN cursor
tl; dr
The cursor is not a random number, but is actually a reverse-bitwise number that indicates the index on a hash table, where redis stores the keys for each database. By reversing the cursor, you can see your progress while SCANning!
See the code and comments below if you’re in a hurry, or see the explanation below if you want more insights.
function reverseBits($cursor, $pow) {
//This is probably not the fastest way to invert a binary
//number. If you want speed, you could probably do a conversion
//from little to big endianness
//Convert from decimal to a binary string
$bin = decbin($cursor);
//Pad the string on the left in order to have $pow chars
$bin = str_pad($bin, $pow, "0", STR_PAD_LEFT);
//Reverse string, then convert back to decimal
return bindec(strrev($bin));
}
function scanProgress($cursor, $totalKeys) {
//Each database in redis is a hash table with size 2^x, depending
//on how many keys are present. To find x, we need to find the
//closest next power of two
$nextPowerOfTwo = ceil(log($totalKeys)/log(2));
//Calculate the hash table size
$hashTableSize = pow(2, $nextPowerOfTwo);
//Get how many keys were read from the cursor by reversing
//the binary representation of the cursor
$hashTableIndex = reverseBits($cursor, $nextPowerOfTwo);
//Calculating percent is now easy, the proportion
//is $hashTableIndex : $hashTableSize = x : 100
$percent = $hashTableIndex * 100 / $hashTableSize;
return $percent;
}
//To use:
$redis->select(10);
$totalKeys = $redis->dbSize();
$cursor = 0;
while (false !== ($keys = $redis->scan($cursor))) {
$percent = scanProgress($cursors, $totalKeys);
echo "Iteration $cursor, progress $percent%";
}
function reverseBits(cursor, pow) {
//This is probably not the fastest way to invert a binary
//number. If you want speed, you could probably do a conversion
//from little to big endianness
//Convert from decimal to a binary string
let bin = cursor.toString(2);
//Pad the string on the left in order to have $pow chars
bin = bin.padStart(pow, "0");
//Reverse string, then convert back to decimal
return parseInt(bin.split("").reverse().join(""), 10);
}
function scanProgress(cursor, totalKeys) {
//Each database in redis is a hash table with size 2^x, depending
//on how many keys are present. To find x, we need to find the
//closest next power of two
const nextPowerOfTwo = Math.ceil(Math.log(totalKeys)/Math.log(2));
//Calculate the hash table size
const hashTableSize = Math.pow(2, nextPowerOfTwo);
//Get how many keys were read from the cursor by reversing
//the binary representation of the cursor
const hashTableIndex = reverseBits(cursor, nextPowerOfTwo);
//Calculating percent is now easy, the proportion
//is keysRead : hashTableSize = x : 100
const percent = hashTableIndex * 100 / hashTableSize;
return percent;
}
//To use:
!async function() {
await redis.select(10); //Select a db
const totalKeys = await redis.dbSize();
let cursor = 0;
while (false !== (keys = await redis.scan(cursor))) {
const percent = scanProgress(cursors, totalKeys);
console.log(`Iteration ${cursor}, progress ${percent}%`;
}
}()
How the cursor works
Let’s imagine we have a database with 200 keys. To store N keys, Redis reserves a hash table bigger than N, so that it doesn’t have to reserve a bigger or smaller space everytime you delete or add keys. Namely it reserves a number that follows the power of 2, so that the following is true: 2^x > N. In this case, the closest power of 2 bigger than 200 is 8 (math).
$totalKeys = $redis->dbSize();
$nextPowerOfTwo = ceil(log($totalKeys)/log(2));
$hashTableSize = pow(2, $nextPowerOfTwo);
So, in this case redis reserves a hash table as big as 2^8, that is 256 or in binary 100000000. As a result, the hash table of a 200 keys database goes from index 00000000 to index 100000000. Once you use more or less keys than that, Redis will increase or decrease that power of 2, with a process called rehashing, see below for this topic.
Back to the cursor, what Redis does is take each cursor and reverse the binary value: by doing so it obtains an actual index, one that in our example is between 00000000 to index 100000000. Starting from that index, Redis increase the index while looping over the hash table, until at least COUNT keys are found, then reverse the binary again, converting it to decimal and returning it to you. So for example, with the same database with 200 keys, SCAN 0 COUNT 10 could follow this flow:
COMMAND BINARY SWAPPED NEW BIN DECIMAL SWAPPED NEW CURSOR
SCAN 0 00000000 00000000 00001010 10 01010000 80
SCAN 80 01010000 00001010 00011110 30 01111000 120
SCAN 120 01111000 00011110 00101000 40 00010100 20
SCAN 20 ...
The index increase (column DECIMAL) is not linear because Redis can read multiple indexes until it finds COUNT keys, and in the same index there can be more than one key. That’s why Redis can sometimes return more keys than there are in COUNT.
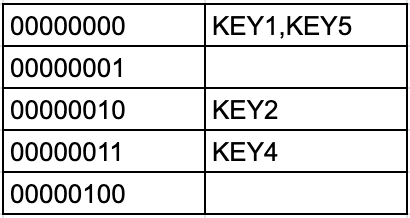
You can also see that all the binary numbers have 8 bits each, which is same as the corresponding power of 2, which is important to maintain the correct index when reversing using strings. 80 in binary is 1010000 (usually you can discard the leftmost 0), but inverted is 0000101 (5 in decimal). 80 in binary with left padding to 8 bits becomes 01010000 which inverted is 00001010 (10 in decimal form). You can see that it’s quite an error, just for a missing 0 😑.
$binary = decbin($cursor);
//After converting to binary, pad the binary string
//to the correct number of bits ($pow)
$binary = str_pad($binary, $pow, "0", STR_PAD_LEFT);
//Here we have the actual hash table position!
$hashTableIndex = bindec(strrev($binary));
After reversing the bits of the cursor, you can do a simple proportion to see at which percent you’ve come along while using SCAN:
$percent = $hashTableIndex * 100 / $hashTableSize;
echo "Iteration $cursor, progress $percent%";
And you’ll have this:
Iterator 80, progress 3.90625%
Iterator 120, progress 11.71875%
Iterator 20, progress 15.625%
More on the topic
If you want to read more about how keys are organized inside the hash table, why Redis swaps the binary of a number, and how rehashing works, you can read Making sense of Redis’ SCAN cursor.
If you want to read a detailed explanation on how SCAN works directly from Redis’ source code, read How the Redis Hash Table Scan Function Works.